MXNet で CNN
Jupyter でライブ手書き文字認識
2016/05/21 機械学習 名古屋 第4回勉強会
後藤 俊介 ( @antimon2 )
自己紹介¶
MXNet とは?¶
- dmlc mxnet(MXNet.jl)
- 2015/10 に出たばかりの新しいフレームワーク。
- Julia, Python, R, Go, JavaScript などに対応した DeepLearning フレームワーク。
- 記述の簡潔さと、(それに伴う)「効率」と「柔軟性」の両立。
- 処理のコア部分は C(C++) で記述されている(それにより軽量性と多言語対応を実現している)。
MXNet で CNN 構築¶
準備¶
In [1]:
using MXNet
CNN構築1¶
入力〜2つの畳み込み層:
In [2]:
# input
data = mx.Variable(:data)
# first conv
conv1 = @mx.chain mx.Convolution(data=data, kernel=(5,5), num_filter=32) =>
mx.Activation(act_type=:relu) =>
mx.Pooling(pool_type=:max, kernel=(2,2), stride=(2,2))
# second conv
conv2 = @mx.chain mx.Convolution(data=conv1, kernel=(5,5), num_filter=64) =>
mx.Activation(act_type=:relu) =>
mx.Pooling(pool_type=:max, kernel=(2,2), stride=(2,2))
Out[2]:
CNN構築2¶
全結合層・ドロップアウト・出力層:
In [3]:
# first fully-connected
fc1 = @mx.chain mx.Flatten(data=conv2) =>
mx.FullyConnected(num_hidden=1024) =>
mx.Activation(act_type=:relu)
# dropout
dp_fc1 = mx.Dropout(fc1, p=0.5)
# second fully-connected
fc2 = mx.FullyConnected(data=dp_fc1, num_hidden=10)
# softmax loss
cnn = mx.SoftmaxOutput(data=fc2, name=:softmax)
Out[3]:
MNIST データ取得¶
In [4]:
# データ取得(データプロバイダ生成)
batch_size = 100
# include(Pkg.dir("MXNet", "examples", "mnist", "mnist-data.jl"))
# train_provider, eval_provider = get_mnist_providers(batch_size)
data_name = :data
label_name = :softmax_label
flat = false
train_provider = mx.MNISTProvider(image="MNIST_data/train-images-idx3-ubyte",
label="MNIST_data/train-labels-idx1-ubyte",
data_name=data_name, label_name=label_name,
batch_size=batch_size, shuffle=true, flat=flat, silent=true)
eval_provider = mx.MNISTProvider(image="MNIST_data/t10k-images-idx3-ubyte",
label="MNIST_data/t10k-labels-idx1-ubyte",
data_name=data_name, label_name=label_name,
batch_size=batch_size, shuffle=false, flat=flat, silent=true)
Out[4]:
モデル構築・最適化(準備)¶
In [5]:
# モデル setup
model = mx.FeedForward(cnn, context=mx.cpu())
# optimization algorithm
optimizer = mx.SGD(lr=0.05, momentum=0.9, weight_decay=0.00001)
# save-checkpoint callback
save_checkpoint = mx.do_checkpoint("MNIST_CNN3")
Out[5]:
最適化(実施)¶
In [ ]:
# fit parameters
mx.fit(
model,
optimizer,
train_provider,
n_epoch=30,
eval_data=eval_provider,
callbacks=[save_checkpoint])
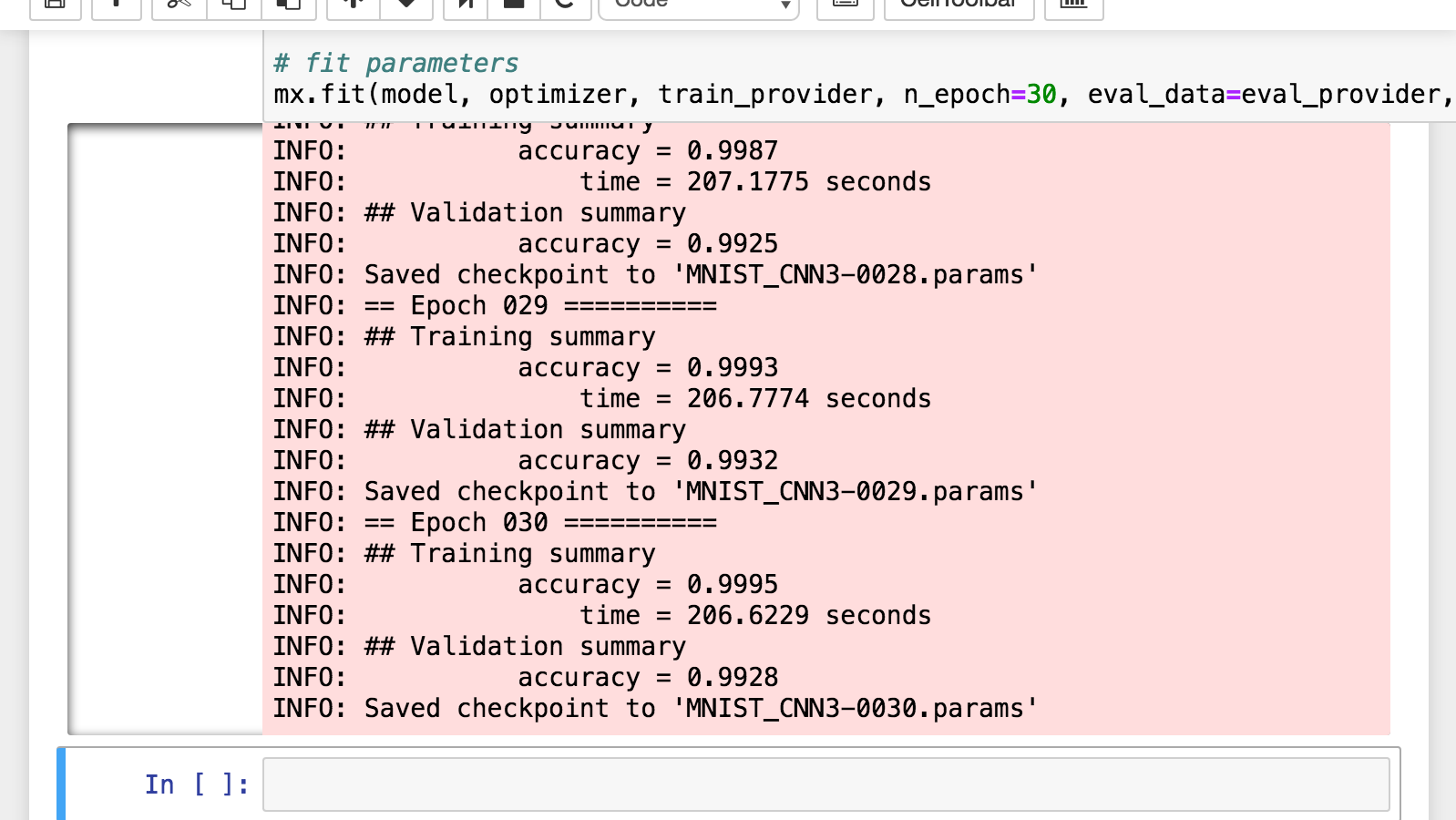
出力例:
チェックポイントの利用¶
チェックポイントの読込¶
MNIST_CNN3_TRAINED-symbol.json、MNIST_CNN3_TRAINED-0030.params の2ファイルが作業ディレクトリに存在する前提で:
In [6]:
model = mx.load_checkpoint("MNIST_CNN3_TRAINED", 30, mx.FeedForward)
Out[6]:
追加学習¶
In [ ]:
# optimization algorithm
optimizer = mx.SGD(lr=0.05, momentum=0.9, weight_decay=0.00001)
# save-checkpoint callback
save_checkpoint = mx.do_checkpoint("MNIST_CNN4")
# re-train
mx.fit(model, optimizer, train_provider, n_epoch=30, eval_data=eval_provider, callbacks=[save_checkpoint])
学習済データを利用した推測¶
In [7]:
batch = first(eval_provider)
idxs = rand(1:batch_size, 3)
images = copy(mx.get(eval_provider, batch, :data))[:,:,:,idxs]
provider = mx.ArrayDataProvider(images)
results = mx.predict(model, provider)
Out[7]:
In [10]:
f, axs = PyPlot.subplots(1, 3, sharey=true, figsize=(10, 3))
for i = 1:3
image = reshape(images[:,:,:,i], 28, 28)'
axs[i][:imshow](image, cmap=get_cmap("Greys"))
axs[i][:set_title]("Classified as: $(indmax(results[:,i])-1)")
end

ライブ手書き数字認識¶
《デモ》
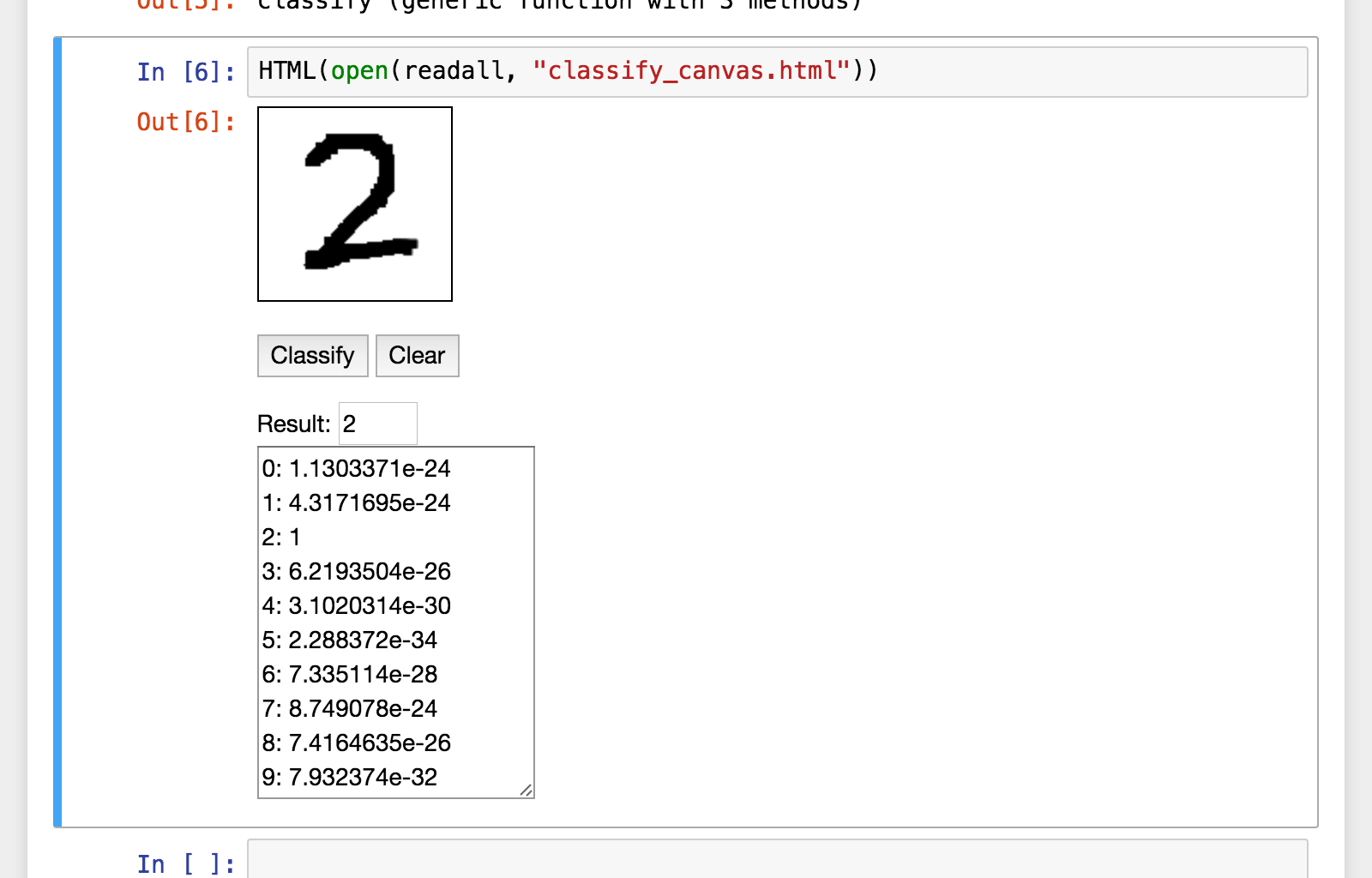
実行例:
参考¶
- dmlc mxnet
- MXNet.jl
- The Julia Language(本家サイト、英語)
- Julia - josephmisiti/awesome-machine-learning(Julia の機械学習関連ライブラリのリンクまとめ。英語)
- Project Jupyter
ご清聴ありがとうございます。